.png)
Selected Tags


















.jpg?length=387&name=shutterstock_528688963%20(1).jpg)


















































































.png?length=387&name=Frame%20142%20(1).png)









.png?length=387&name=Through%20Technology%20Webinar%20(500%20x%20330%20px).png)

.png?length=387&name=Episode%202%20Application%20Retirement%20-%20Leveraging%20Data%20Governance%20for%20Success%20%20(2).png)


-1.png?length=387&name=Episode%201%20Best%20Practices%20for%20Email%20Migration%20-%20Managing%20Inactive%20User%20Data%20(1)-1.png)








.png?length=387&name=Steering%20Clear%20of%20the%20Pitfalls%20Essential%20Data%20Governance%20Strategies%20for%20Effective%20AI%20Compliance%20(1).png)




%20(2).png?length=387&name=The%20New%20Data%20Governance%2c%20Risk%20&%20Compliance%20Imperative%20(500%20x%20330%20px)%20(2).png)

%20(4).png?length=387&name=Data%20governance%20landscape%20%20(500%20x%20330%20px)%20(4).png)



.png?length=387&name=a%20data%20governance%20roadmap%20even%20a%20robot%20would%20approve%20(1200%20x%20627%20px).png)







.png?length=387&name=PST%20Migration%20Guide%20Cover%20(500%20%C3%97%20330%20px).png)






.png?length=387&name=Untitled%20design%20(35).png)
.png?length=387&name=Untitled%20design%20(34).png)
.png?length=387&name=Untitled%20design%20(33).png)
.png?length=387&name=Untitled%20design%20(32).png)
.png?length=387&name=Untitled%20design%20(31).png)
![Discussing Canadian Privacy Legislation: Digital Charter Implementation Act [Bill C-27]](https://www.archive360.com/hs-fs/hubfs/Discussing%20Canadian%20Privacy%20Legislation%20Digital%20Charter%20Implementation%20Act%20(Bill%20C-27).png?length=387&name=Discussing%20Canadian%20Privacy%20Legislation%20Digital%20Charter%20Implementation%20Act%20(Bill%20C-27).png)
.png?length=387&name=Untitled%20design%20(30).png)
![Discussing Canadian Privacy Legislation | Digital Charter Implementation Act [C-27/CPPA]](https://www.archive360.com/hs-fs/hubfs/Graphics%20for%20C-27%20(Canada)%20webinar%20(600%20%C3%97%20500%20px).png?length=387&name=Graphics%20for%20C-27%20(Canada)%20webinar%20(600%20%C3%97%20500%20px).png)
%20(3).png?length=387&name=GovLoop%20Webinar%20(600%20%C3%97%20600%20px)%20(3).png)
.png?length=387&name=Webinar%20Why%20Zero%20Trust%20is%20Important%20(600%20%C3%97%20500%20px).png)

.png?length=387&name=Untitled%20design%20(19).png)



.png?length=387&name=Bill%20tolson%20podcast%20episode%20she%20said%20privacy%20he%20said%20security%20(450%20%C3%97%20250%20px).png)

.png?length=387&name=Untitled%20design%20(15).png)


.png?length=387&name=Images%20for%20videos%20in%20HubDB%20table%20(2).png)
.png?length=387&name=Osterman%20research%20white%20paper%20%20why%20zero%20trust%20is%20important%20(1).png)
.png?length=387&name=Untitled%20design%20(18).png)

.png?length=387&name=Untitled%20design%20(16).png)

.png?length=387&name=Images%20for%20videos%20in%20HubDB%20table%20(1).png)

.png?length=387&name=Untitled%20design%20(17).png)
.png?length=387&name=Images%20for%20videos%20in%20HubDB%20table%20(3).png)


.png?length=387&name=Images%20for%20videos%20in%20HubDB%20table%20(4).png)
.png?length=387&name=Images%20for%20videos%20in%20HubDB%20table%20(5).png)








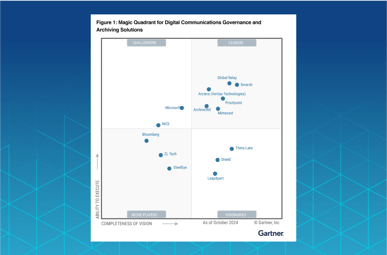
.png?length=387&name=2%20A%20Leader%20in%20the%20Gartner%C2%AE%20Magic%20QuadrantTM%20for%20Digital%20Communications%20Governance%20and%20Archiving%20Solutions%20(900%20x%20450%20px).png)
Get the latest in your inbox.
Stay up to date on industry news, customer spotlights and the most recent information on cloud based archiving, data privacy, data management and data migration.
Load More
Stay up to date on industry news, customer spotlights and the most recent information on cloud based archiving, data privacy, data management and data migration.