Archive360 Unlocks Enterprise Archive Data for AI, Analytics, and Compliance on Snowflake AI Data Cloud June 3, 2025 Archive360 integrates with Snowflake to unlock enterprise archive data for AI, analytics, and compliance, ensuring seamless governance and faster insights at Snowflake Summit 2025. Learn More
Archive360 Launches a Governed AI-Ready Data Cloud to Meet Future Needs of the Modern Enterprise May 13, 2025 Archive360 launches an AI-ready data cloud platform, providing governed, secure, and compliant data for enterprises to enhance AI and analytics capabilities. Learn More
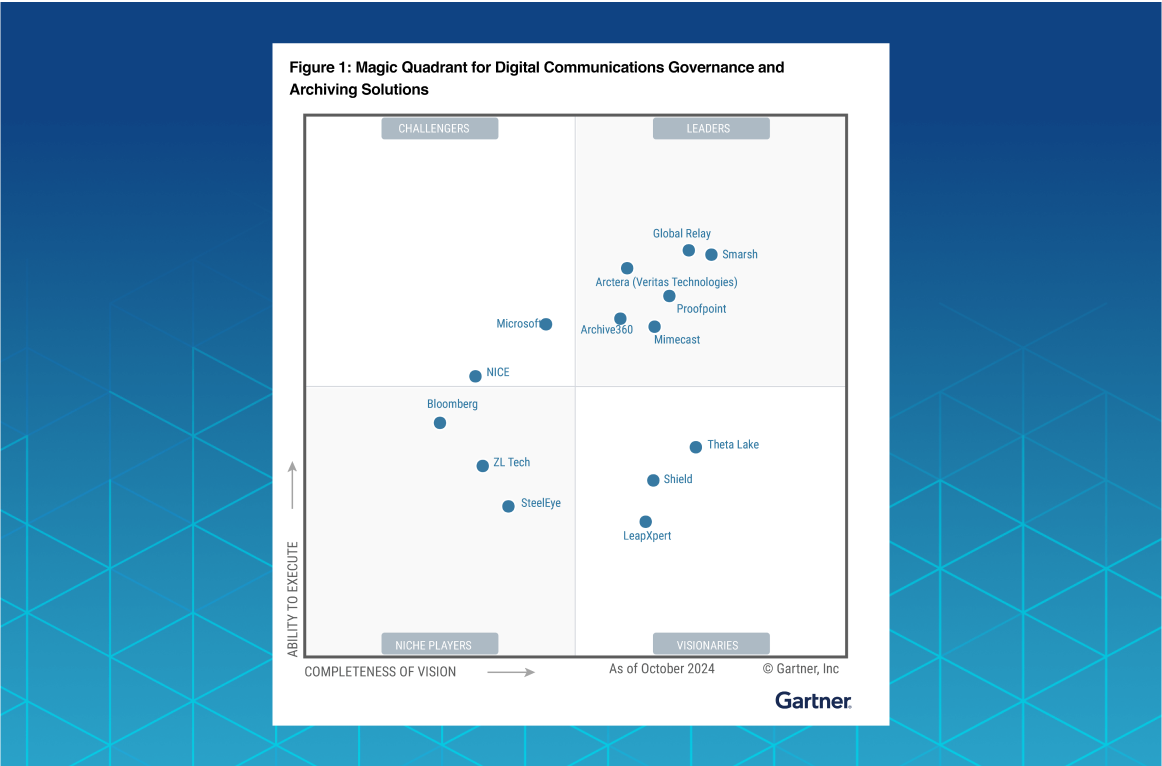
Archive360 Named 2025 Gartner Leader | DCGA January 14, 2025 Archive360 Recognized for Completeness of Vision and Ability to Execute in First-Ever Magic Quadrant for This Market Learn More
Archive360 & KiZAN: Cloud Migration Win February 13, 2024 Archive360 and KiZAN Partner to complete a major cloud migration for leading healthcare provider, ensuring data security and compliance Learn More
Top 10 US Bank Projects More than $39 Million Savings January 31, 2024 Archive360 helps a top US bank retire legacy systems, automate data retention, save $39M, and centralize data management for compliance and efficiency. Learn More
VNEXT & Archive360 Strategic Alliance December 18, 2023 Discover how VNEXT Group and Archive360 leverage Microsoft 365 and Azure expertise to enhance unified data governance. Read the blog. Learn More